在這篇文章中,我們會一步一步拆解用python爬蟲的方式抓取屈臣氏門市的門市分布資料,主要會用到Beautiful Soup套件和requests套件。當然,我們不會只講python的部分,也會說明如何善用
一、觀察網頁回傳資料的邏輯
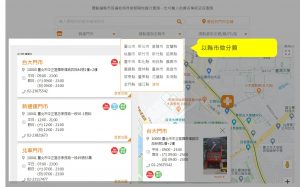
來到門市查詢的頁面,因為我們要抓出所有門市的位置,而通常店家都會分縣市去顯示門市位置,所以我們要先知道網頁上把門市分類顯示的邏輯。
屈臣氏這邊,可以看到他們有分行政區,同一個行政區也有分頁數顯示,這些都是待會可能用到的資訊,先有個印象。

接著就打開網頁開發工具( 通常是按F12 ),切換到Network頁籤,在這裡可以觀察到網頁傳出和回傳的參數。
這裡很明顯看到 town : 基隆市 應該就是行政區的分類,而後面還有個distrct參數,但是沒有送任何值,表示我們不用設定它也可以。到這邊先別急著列出所有縣市去找,我們還有頁數還沒看。

所以先回到查詢門市的頁面,去點第2頁,再回到開發人員工具這邊看看參數有甚麼變化。這時候我們可以發現它多了一個currentPage=2,而我們現在在第2頁,所以需要的參數大概都有了。

知道了傳入的參數之後,接下來要看看回傳給我們的是甚麼格式,一樣在開發人員工具這裡,但這次要從Network頁籤切換到Preview頁籤(或是Response頁籤),可以看到回傳的是HTML格式,所以在Python裡面我們需要用Beautiful Soup套件去解析它。

二、引入相關套件
要讓Python去送出網頁請求來得到我們要的資料,可以使用 requests 套件,而前面有提到,屈臣氏網頁回傳的資料格式是HTML,所以我們需要美湯Beautiful Soup套件來幫忙解析。
import requests
from bs4 import BeautifulSoup as bfPython載入套件是用import
而只想載入套件的部分功能則是from 套件 import 套件功能
至於載入的套件不一定要照套件命名,因為有時候套件名稱落落長,容易打錯,這時候就可以用import 套件 as 想取的名字
所以這裡的 from bs4 import BeautifulSoup as bf 意思就是我要載入bs4的BeautifulSoup功能,然後它名字太長了我想叫它bf就好。
三、網頁傳輸參數
(一) URL和傳入參數
前面有提到,屈臣氏網頁有兩個關鍵參數用來查詢門市分部的資料,一個是行政區town,一個是頁數currentPage。我們可以先建立要呼叫的URL(網頁上問號之前那串)和要傳入的參數(網頁上問號之後那串)。
baseURL = 'https://www.watsons.com.tw/store-finder/getPartialStore?'
param = {
"currentPage": page,
"town": city,
"district":"",
"features":"",
"keyword":""
}(二) 送出查詢
這裡就要用到前面import的requests套件,它可以用來發起HTTP request,也就是可以去造訪上面的URL,有點像我們瀏覽網頁。requests主要有兩大方式去造訪網頁:
1. get : URL上會直接帶入參數,URL上的問號之後那串就是參數
2. post : 不會直接帶參數在URL上,但是打開開發人員工具還是可以看到

知道了屈臣氏是用get方式之後,我們就可以用requests.get( 要造訪的URL , 要傳入的參數 )的方式來取得資料,取到的資料如果有編碼議題就用回傳資料.encoding=”utf-8″來做設定,再來就是用前面載入過的Beautiful Soup,也就是已經被我們命名成bf的功能來解回傳的HTML資料:soup = bf( response.text ,”html5lib” )。
注意到這邊要解析的是response.text,而不是response本身。
response = requests.get( baseURL , params = param )
response.encoding="utf-8"
soup = bf( response.text ,"html5lib" )四、解析出需要的資訊
(一) 找出呈現地址的HTML元素
要抓門市分布的位置,最重要的資訊當然就是位置了!有些網頁會直接有經緯度,有些只有地址,這就比較麻煩一點,屈臣氏就只有地址。
首先,我們使用開發人員工具裡面的元素選取工具來點選網頁上的地址,就能看到包含地址的網頁元素的class,我們可以用Beautiful Soup來找出符合class = shopStreetName的所有元素,也就是我們要的門市分布資訊。
同樣方法,我們也可以找出門市的名稱,它的網頁元素是class =resultShopName。


(二) 用find_all()找出符合的元素
接下來就用Beatiful Soup套件來找出所有符合條件的網頁元素。語法是:
soup.find_all( 元素tag , { 要篩選的屬性 , 屬性的值 } )
以屈臣氏的地址為例,要篩選的屬性就是class,屬性的值是’shopStreetName’,所以寫出來會像address = soup.find_all(‘font’ , {‘class’ , ‘shopStreetName’})
address = soup.find_all('font' , {'class' , 'shopStreetName'})
shopname = soup.find_all('font' , {'class' , 'resultShopName'})五、用迴圈爬取所有縣市的門市
(一) 對頁數做迴圈
最前面有提到屈臣氏的門市分布有分頁顯示,因為沒辦法知道每個縣市會有幾個分頁,所以這邊我用的方式是用While迴圈,只要當頁面上有抓出地址元素的話,就當作是還在頁數範圍內,就執行程式,執行完記得page要加1,才會到下一頁,不然會一直停留在第一頁無窮迴圈。page會當成要傳送出去的HTML參數:currentPge的值。
因為地址我們是設為 address = soup.find_all(‘font’ , {‘class’ , ‘shopStreetName’})。所謂頁面上有抓出地址元素就是當address這個陣列的長度等於0 ( if len(address) == 0 ),代表沒抓到任何東西,實際上這頁不存在,前一頁就是最後一頁。
例如,在第2頁,address 的長度等於10,表示這一頁有門市資料,我們就執行程式抓取,但到了第3頁,address 的長度等於0,就表示這個縣市資料抓完了,可以抓下個縣市的。這邊要注意,迴圈結束之前一定要更新address變數,不然下一個迴圈address永遠會長度大於0,程式就不會停止。
page = 1
storeLength = 1
while storeLength != 0:
baseURL = 'https://www.watsons.com.tw/store-finder/getPartialStore?'
param = {
"currentPage": page,
"town": city,
"district":"",
"features":"",
"keyword":""
}
response = requests.get( baseURL , params = param )
response.encoding="utf-8"
page += 1
soup = bf( response.text ,"html5lib" )
address = soup.find_all('font' , {'class' , 'shopStreetName'})
shopname = soup.find_all('font' , {'class' , 'resultShopName'})
storeLength = len(address)(二) 對縣市做迴圈
這邊我取得縣市的方式是用javascript來取得,我們可以把所有縣市放到一個陣列裡面,接著用迴圈的方式一個一個取得,然後當成要傳送出去的HTML參數:city的值。
admins = ["基隆市","台北市","新北市","桃園市","新竹市","新竹縣","苗栗縣","台中市","彰化縣","南投縣","雲林縣","嘉義市","嘉義縣","台南市","高雄市","屏東縣","台東縣","花蓮縣","宜蘭縣","澎湖縣","金門縣","Central"](三) 整合所有程式!
用python爬蟲抓取屈臣氏門市位置資料的步驟大概是:
1. 引用必要套件
2. 對縣市進行迴圈
3. 對頁數進行迴圈
4. 組合參數傳送HTML請求
5. 取得該縣市所有頁數的地址和門市名稱資料
在這邊我用兩個陣列來記錄取得的地址和門市名稱:
allAddress : 存放所有門市地址
names : 存放所有門市名稱
會分兩個變數主要是門市分布資料要能拿來用,之後還必須把地址轉座標才能用,而地址轉座標我是用內政部提供的API進行轉換:
https://gist-geo.motc.gov.tw/api/V2/Locator/AddressLocation/ + 地址
轉換完之後再把門市名稱和座標用python存成geojson檔案,這部分不在本篇文章描述。
import requests
from bs4 import BeautifulSoup as bf
admins = ["基隆市","台北市","新北市","桃園市","新竹市","新竹縣","苗栗縣","台中市","彰化縣","南投縣","雲林縣","嘉義市","嘉義縣","台南市","高雄市","屏東縣","台東縣","花蓮縣","宜蘭縣","澎湖縣","金門縣","Central"]
allAddress = []
names = []
for city in admins:
print( city )
page = 1
storeLength = 1
while storeLength != 0:
baseURL = 'https://www.watsons.com.tw/store-finder/getPartialStore?'
param = {
"currentPage": page,
"town": city,
"district":"",
"features":"",
"keyword":""
}
response = requests.get( baseURL , params = param )
response.encoding="utf-8"
page += 1
soup = bf( response.text ,"html5lib" )
address = soup.find_all('font' , {'class' , 'shopStreetName'})
shopname = soup.find_all('font' , {'class' , 'resultShopName'})
storeLength = len(address)
for n in range(len(shopname)):
if address[n].text not in allAddress:
names.append( shopname[n].text )
allAddress.append( address[n].text )想知道其他商家的爬蟲,可以參考 : Python網路爬蟲-康是美門市分布
小額支持鍾肯尼
如果我的文章有幫助到你,歡迎你點這裡開啟只要40元的小額贊助連結,可以贊助我一杯咖啡錢;我會更有動力繼續寫作,幫助大家解決更多問題。